
🔑数据结构_第二章:线性表
第二章:线性表
(一)线性表的定义、基本操作概述
1、定义
线性表是具有相同数据类型的n(n>0)个数据元素的有限序列,其中n为表长,n为0时为空表。
若用L命名线性表,则其一般表示为:
$$
L = (a_1, a_2, …, a_i, a_{i+1}, …, a_n)
$$
a1为表头元素,an为表尾元素。- 除第一个元素外的每个元素都只有一个直接前驱,除最后一个元素外的每个元素都只有一个直接后驱。
2、线性表的特点
- 表中的元素个数有限。
- 表中元素具有逻辑上的顺序性,表中元素有其先后次序。
- 表中元素每个都是数据元素,每个元素都是单个元素。
- 表中元素的数据类型都相同,每个元素占有相同大小的存储空间。
- 表中元素具有抽象性,即仅讨论元素间的逻辑关系,而不考虑元素究竟表示什么内容。
注:线性表是一种逻辑结构,表示元素之间一对一的相邻关系。而顺序表和链表是指存储结构,不要混淆!
2、可以进行的基本操作
①改
创建/初始化线性表:
InitList(&L):构造一个空的线性表。销毁/删除线性表:
DestroyList(&L):销毁表并释放其内存空间。*更改某个元素的值:
可自定义。
②查
按值查找元素:
LocateElem(L,e):在表L中查找具有给定关键字值的元素。按位查找元素:
GetElem(L,i):获取表L中第第i个元素的值。求表长:
Length(L):返回表L中元素的个数。判空操作:
Empty(L):若L为空表,返回true,否则返回false。
③增
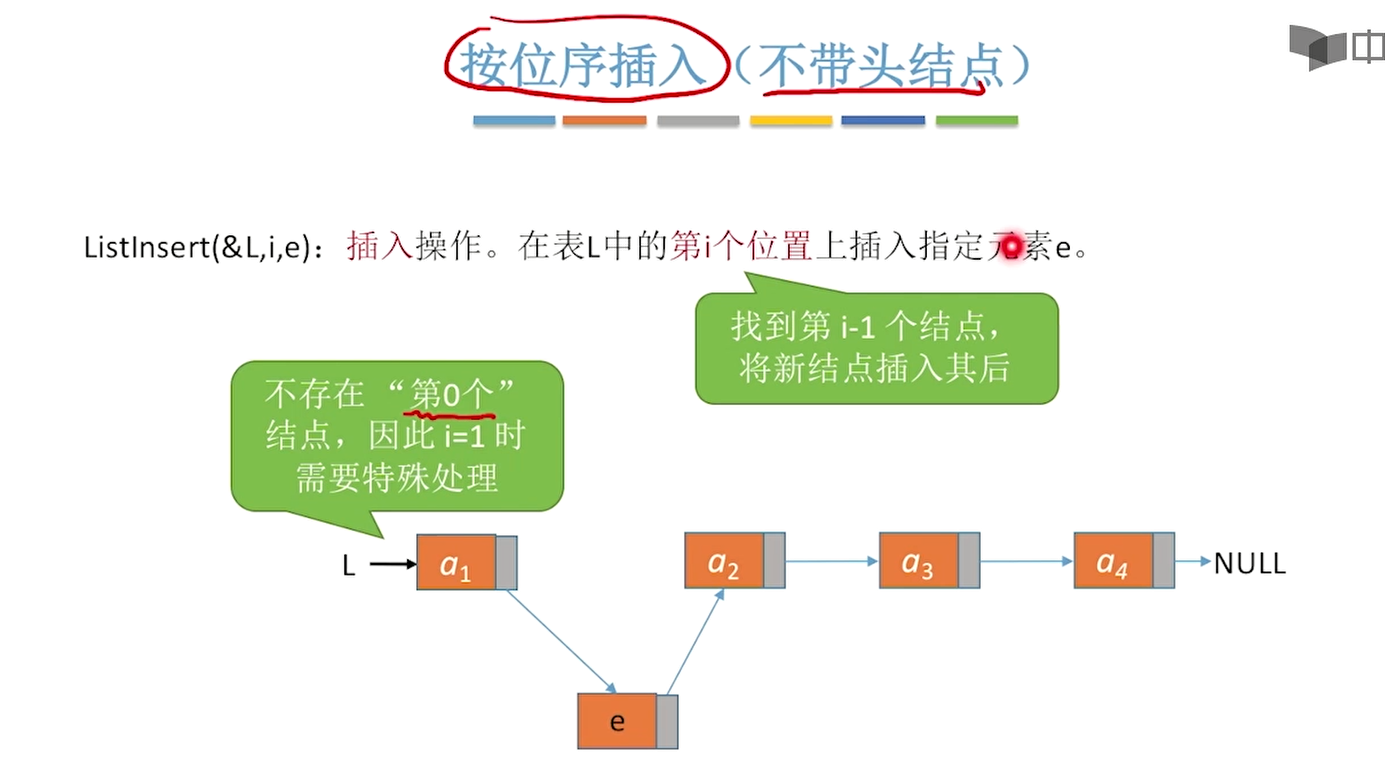
插入元素:
ListInsert(&L,i,e):在表L的第i个位序插入元素e。(前插)特殊情况:
- 在表第一个结点之前插入。
- 在表末尾插入。
④删
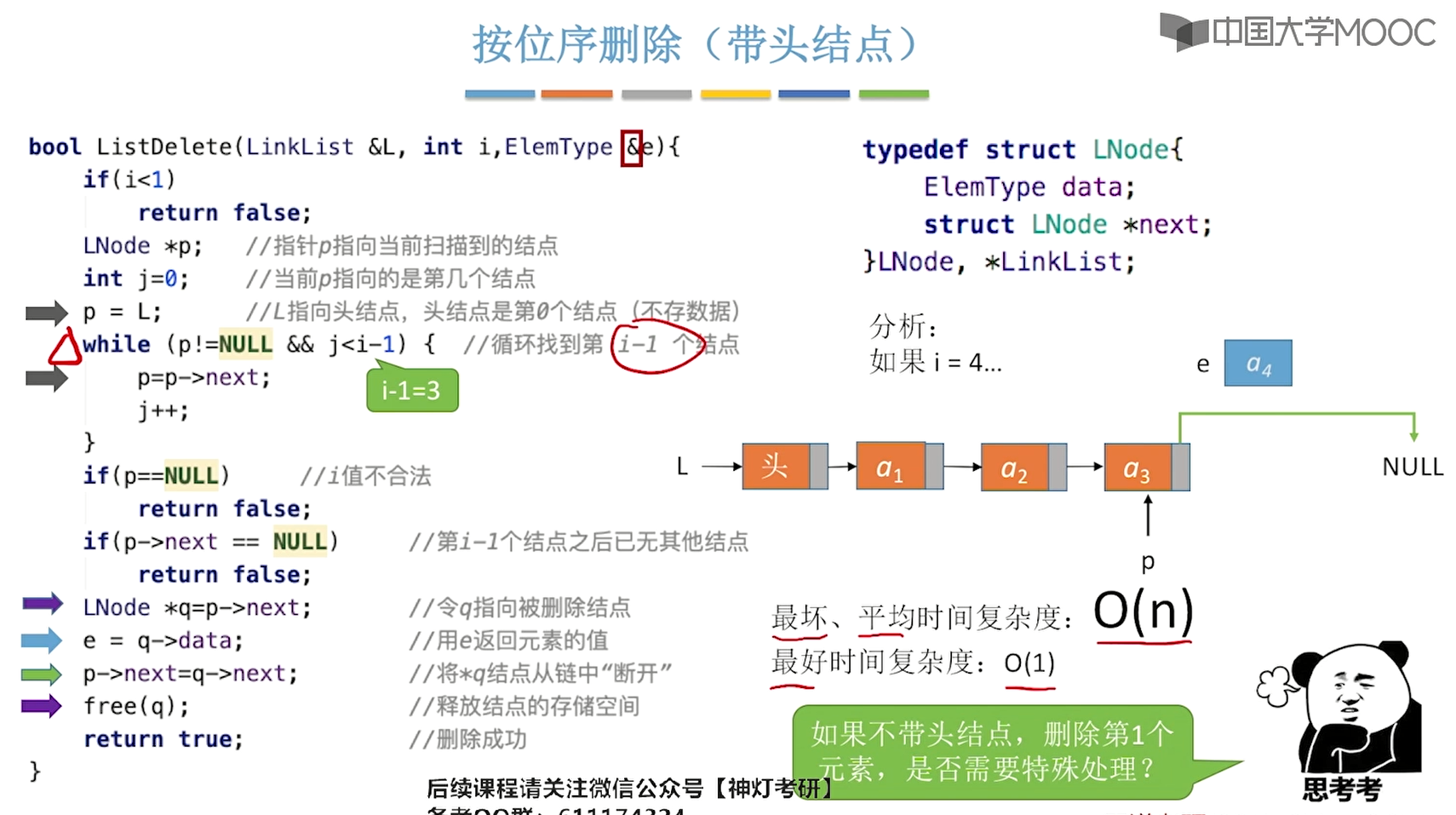
删除元素:
ListDelete(&L,i,&e):删除表L的第i个元素,并用e返回被删元素的值!特殊情况
- 删除第一个结点
- 删除末尾结点
*注:①基本操作的实现取决于采取哪种存储结构,存储结构不同,算法的实现也不同。
②符号&代表C++语言中的引用,在C语言中用指针也可以达到同样的效果。
(二)线性表的顺序表示——顺序表
1、概念
线性表描述了一种逻辑上的存储关系,而我们用顺序表可以在物理层面实现这种存储方式。所以,顺序表就是逻辑顺序与物理顺序都相同的一种实现线性表的方式。
- 也是一种随机存储的存储结构。
- 通常用高级程序设计语言中的数组来描述。
2、特点:
- 随机访问。
- 存储密度高,每个节点只存储数据元素。
- 逻辑上相邻的元素物理上也相邻,所以插入和删除操作可能需要移动大量元素。
3、基本操作
(1)插入
向表中第i个位置插入元素e:
1 | //①判断输入值i是否合法,不合法则返回错误信息终止程序运行,合法则下一步; |
- 最好情况:在表尾插入元素,不执行移动,时间复杂度为O(1)。
- 最坏情况:在表头插入元素,所有元素都被移动一次,时间复杂度为O(n)。
- 平均时间复杂度:O(n)。
(2)删除
删除表中第i个位置的元素,并返回删掉元素的内容:
1 | //①判断输入值i是否合法,不合法则返回错误信息终止程序运行,合法则下一步; |
- 最好情况:删除表尾元素,不执行移动,时间复杂度为O(1)。
- 最坏情况:删除表头元素,所有元素都被移动一次,时间复杂度为O(n)。
- 平均时间复杂度:O(n)。
(3)按值查找(顺序查找)
for循环遍历,挨个比较值,返回目标元素索引值。
- 最好情况:查找的元素就在表头,仅需比较一次,时间复杂度为O(1)。
- 最坏情况:查找的元素在末尾或不存在,所有元素都要比较一次,时间复杂度为O(n)。
- 平均时间复杂度:O(2)。
4、代码实现
(1)顺序表的实现——静态分配
1 |
|

(2)顺序表的实现——动态分配
(三)线性表的链式表示——链表
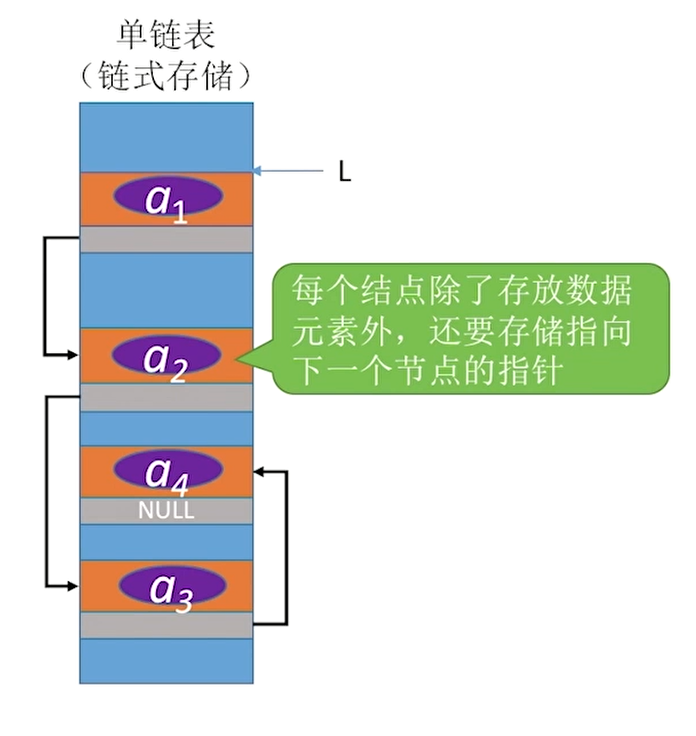
逻辑上相邻,但物理上不相邻的存储方式即为线性表的链式存储。
每个存放数据的结点中有数据域和指针域,除了存放原来的数据,还要存储指向直接后继或直接前驱或其他地方的指针。
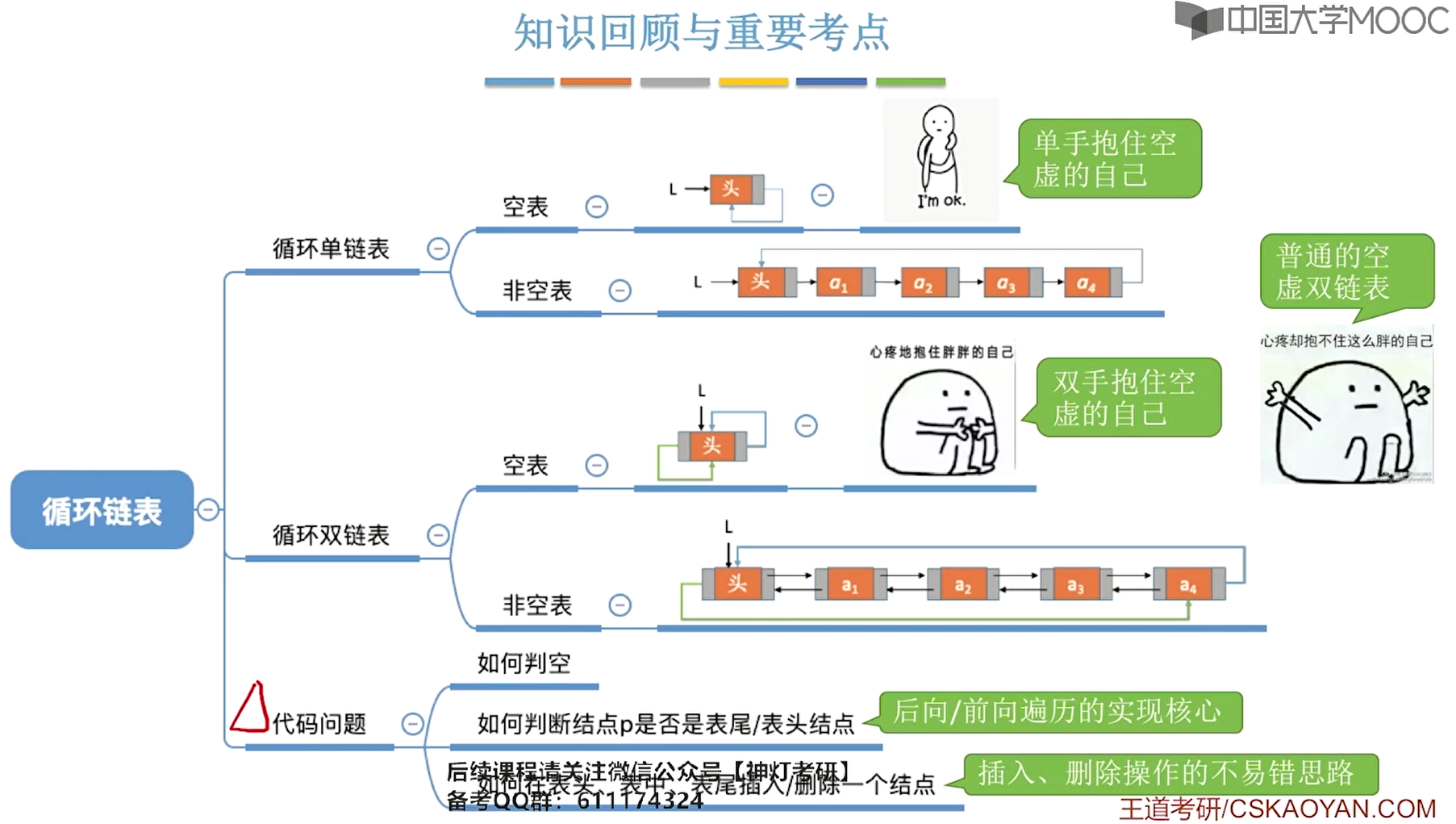
链表有四种:单链表、双链表、循环单链表、循环双链表。
是一种非随机存储的存储结构。
- 优点
- 插入和删除操作不用移动元素,只需修改指针。
- 不需要大量连续的存储空间来存储数据。
- 缺点
- 失去了顺序表可随机存储的优点,因此查找某个特定结点时需要从头遍历依次查找。
- 附加指针域,有浪费空间的缺点。
1、单链表
(1)单链表的创建
基于C的伪代码实现:
1 | typedef struct LNode{ //定义单链表节点类型的结构体 |

自己手撸:
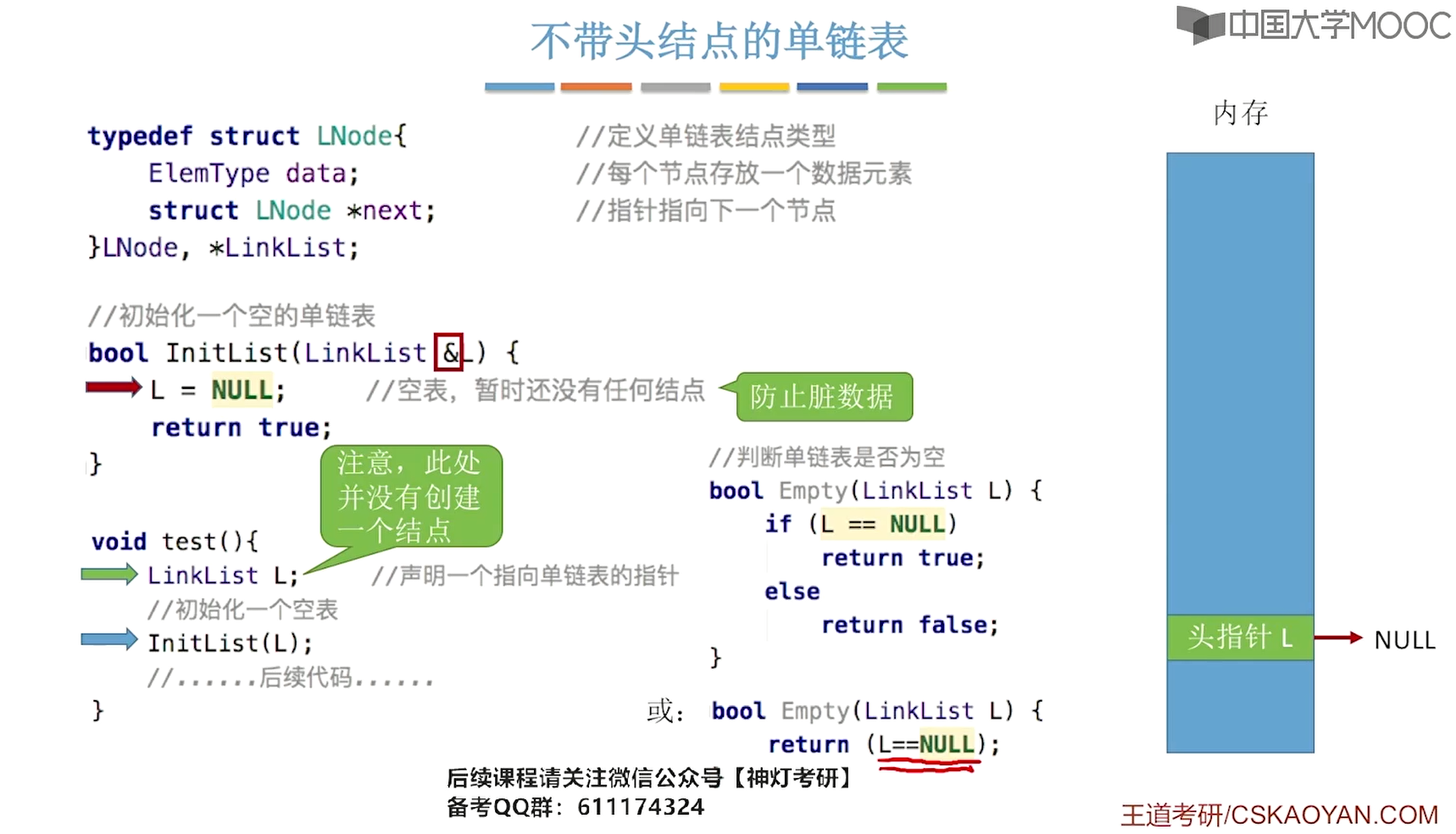
不带头结点:
1
2
3
4
5
6
7
8
9
10
11
12//声明结点结构体
typedef struct LNode{
int data;
struct LNode *L;
}LNode, L_Link;
//声明头结点
L_Link initL_withotHeadNode(){
L_Link L;
L = NULL;
return L;
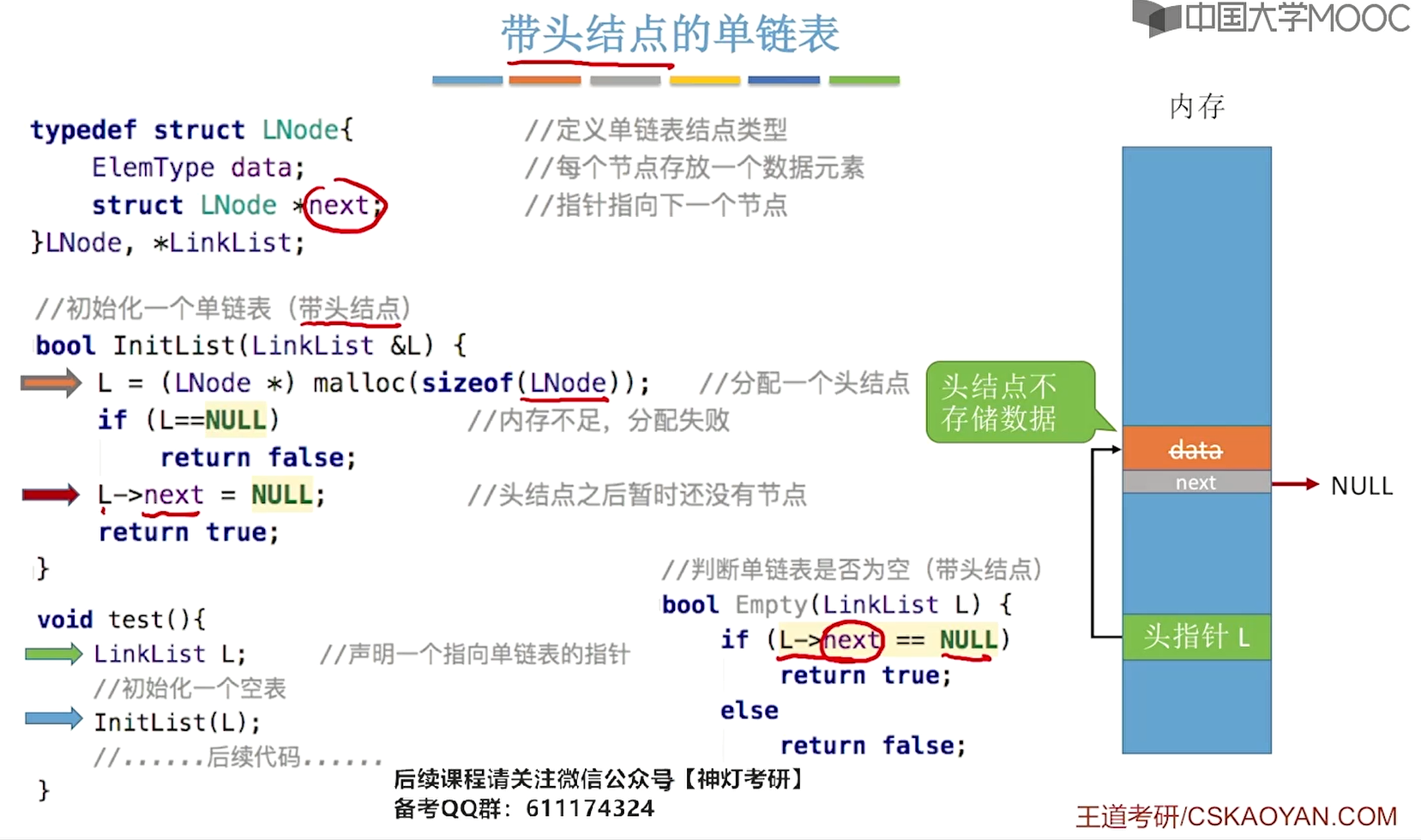
}带头结点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//声明结点结构体
typedef struct LNode{
int data;
struct LNode *L;
}LNode, L_Link;
//声明头结点
L_Link initL_withHeadNode(){
L_Link L = (L_Link)malloc(sizeof(LNode));
//判断空间分配是否成功
if(L == NULL){
printf("空间分配未完成,链表创建失败!");
return L;
}
//头结点的数据域和指针域都为空——NULL
L->data = NULL;
L->next = NULL;
return L;
}判断表是否为空:
1
2
3
4
5
6
7
8
9//不带头结点:
bool emptyList_withoutHeadNode(L_Link L){
return (L == NULL);
}
//带头结点:
bool emptyList_withHeadNode(L_Link L){
return (L->next == NULL);
}
(2)单链表的查找
①按位查找
②按值查找
(3)单链表结点的插入
①前插
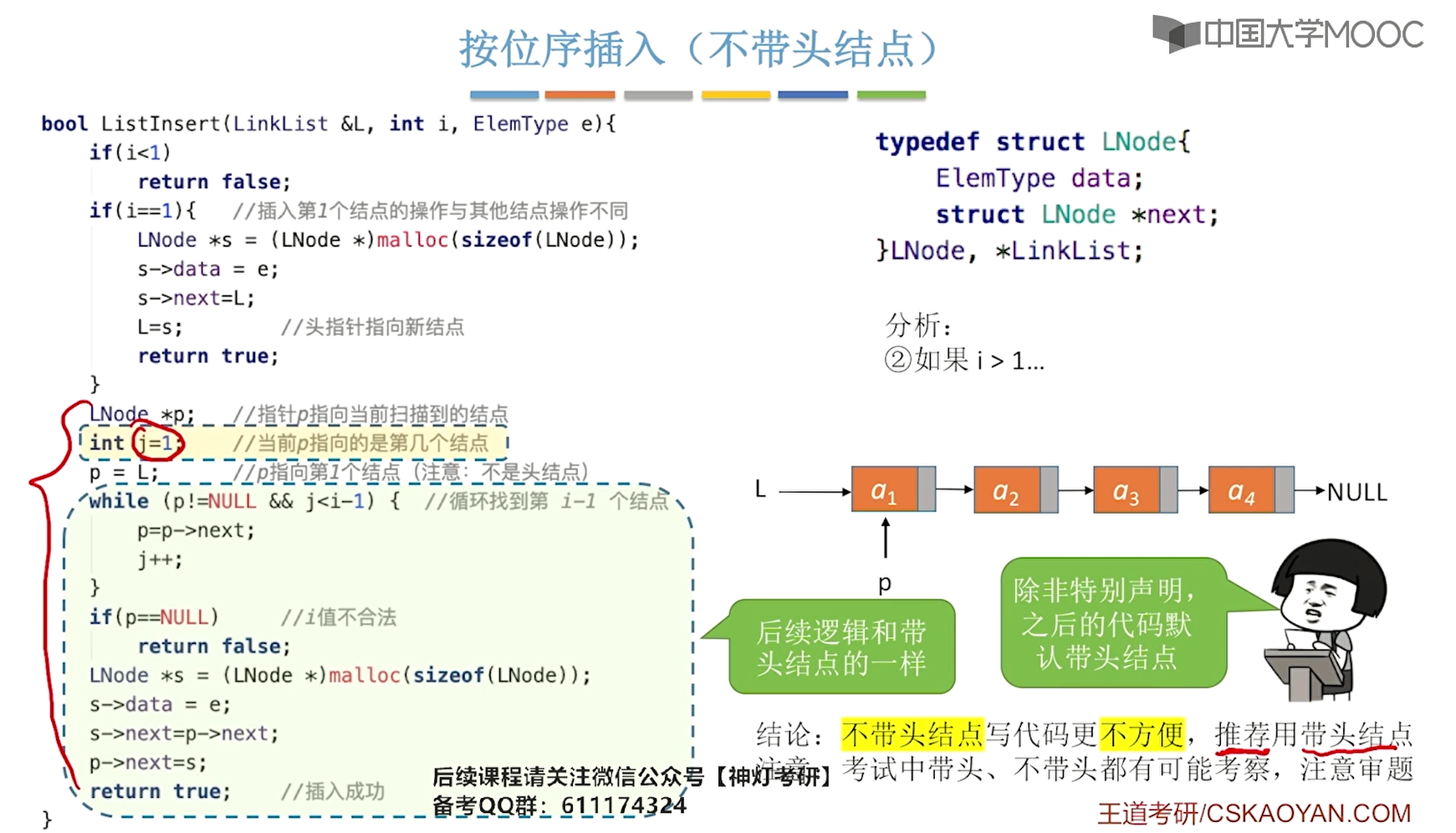
将数据e插入到表L的第i(位序)个位置(之前):
思路1:新建指针p,通过循环遍历使p指向第i-1个结点的位置,然后将新节点插入到p之后。
不带头结点的表:
因为对于不带头结点的表,在表为空时插入第一个结点需要更改头指针,而在其它地方插入都相当于在某个特定节点之后插入,所以需要判断两种情况(以下代码中的第7行):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35L_Link insertL_withoutHeadNode(L_Link L, int i, int e){
//判断i值合法性
if(i < 1){
printf("i值不合法!");
return L;
}
//判断i是否为1,若为1,则创建第一个结点
if(i == 1){
L_Link N1 = (L_Link)malloc(sizeof(LNode));
L = N1;
N1->next = L;//使新结点指向原来L指向的节点,避免断链。若原本是空表,则N1->next为NULL,即尾结点N1指针域为空,合理!
N1->data = e;
return L;
}
//i值不为1,则遍历寻找第i-1个位序的结点再插入
L_Link p = L;
for(int j = 1; j < i-1; j++){ //注:这里j的初始值为1,那么循环体就要比j = 0少运行一次,因此循环结束p就指向了i-1的位置
p = p->next;
}
//以上循环体也可调用按位查找方法来替换:
/*
p = L_Link searchL_num(L, i-1);
*/
//此时指针p指向第i-1个结点
//再判断p值,值为空说明位置不存在
if(p == NULL){
printf("i值不合法!");
return L;
}
L_Link N1 = (L_Link)malloc(sizeof(LNode));
N1->next = p->next;
p->next = N1;
N1->data = e;
return L;
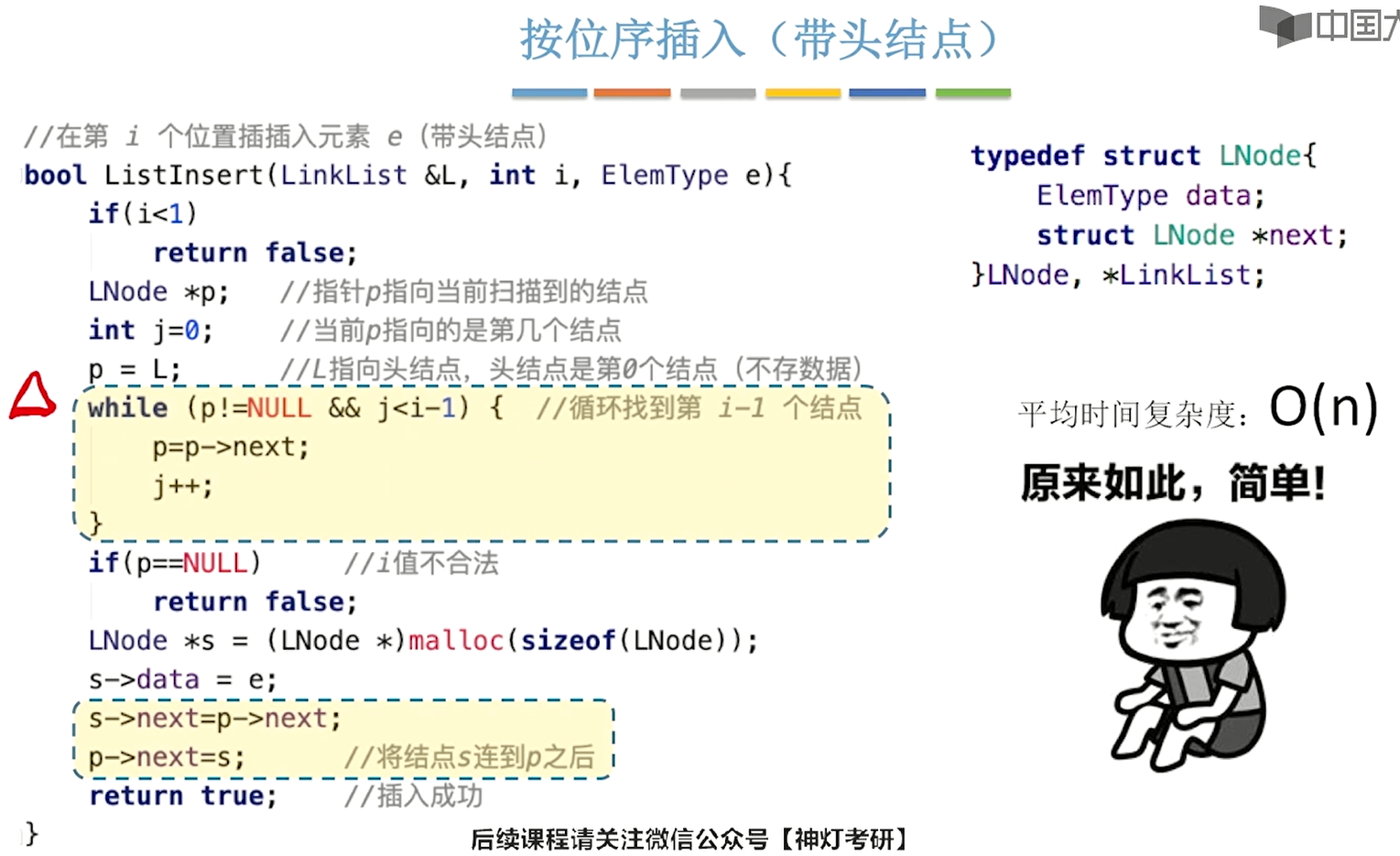
}带头结点的表:
对于带头结点的表,不论在那儿插入都相当于在某个指定节点之后插入,所以不用分情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23L_Link insertL_withHeadNode(L_Link L, int i, int e){
//判断i值合法性
if(i < 1){
printf("i值不合法!");
return L;
}
L_Link p = L;
//挪指针
for(int j = 0; j < i-1; j++){
p = p->next;
}
//此时p指向i-1个结点
//再判断指针位置是否存在
if(p == NULL){
printf("i值不合法!");
return L;
}
L_Link N1 = (L_Link)malloc(sizeof(LNode));
N1->next = p->next;
p->next = N1;
N1->data = e;
return L;
}
思路二:以上方法都需要先循环遍历到第i-1个结点的位置,甚是啰嗦!
新思路:新节点直接插到第i个节点后面,然后交换新节点和第i个结点的数据,效果也是一样的:
1 |
②后插
将数据e插入到表L的第i个元素之后。
思路:
有关链表的增删改查所有手撸源码:
懒得整理了,就这样看吧:
1 |
|
- 单链表的判空:判断指针
L是否为NULL,是则为空。
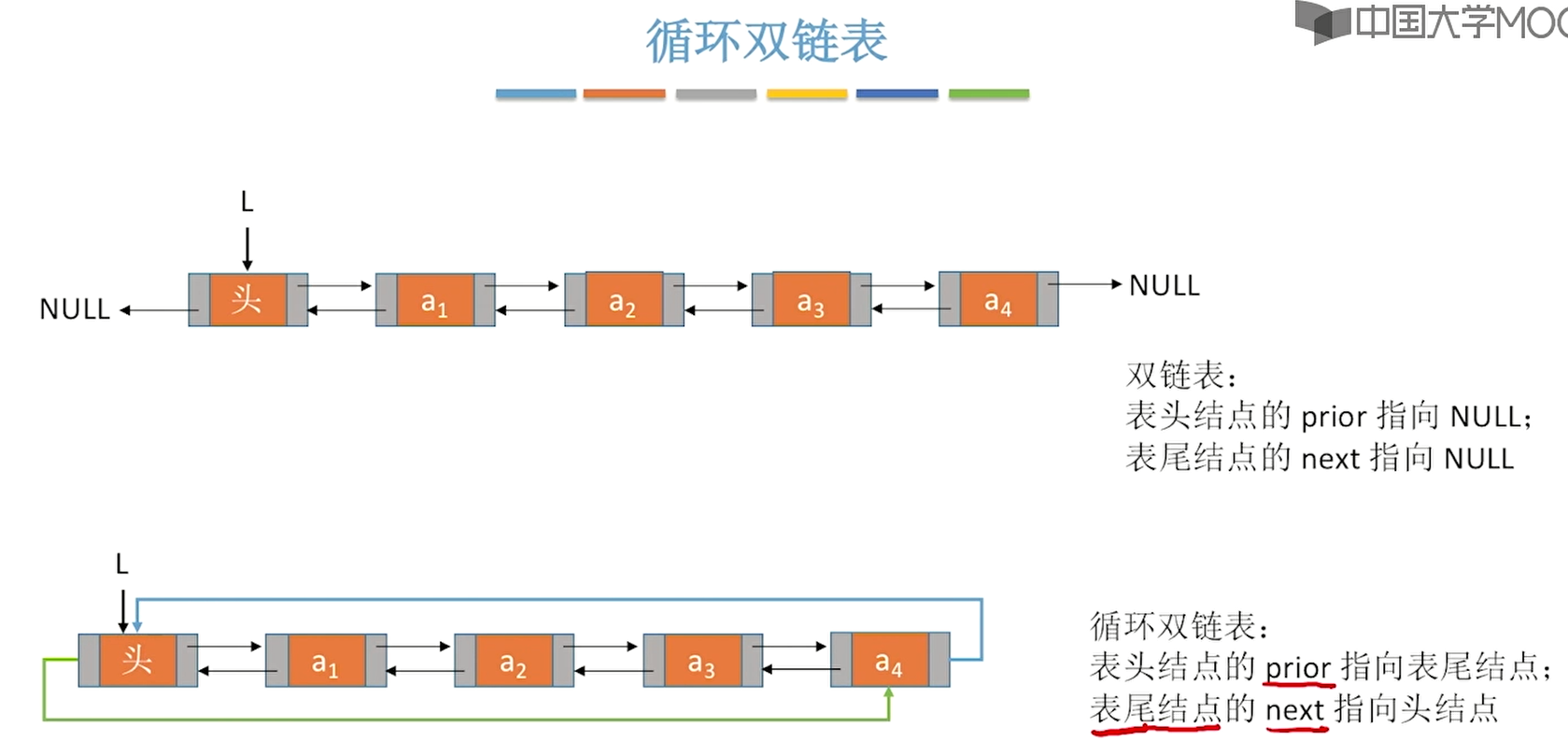
2、双链表
双链表就是每个节点都带有两个指针(域)的结点,第一个指针prior指向前一个结点,第二个next指针指向直接后继结点。
- 解决了单链表无法逆向检索的缺点。
以下讨论的都是带头结点的链表:
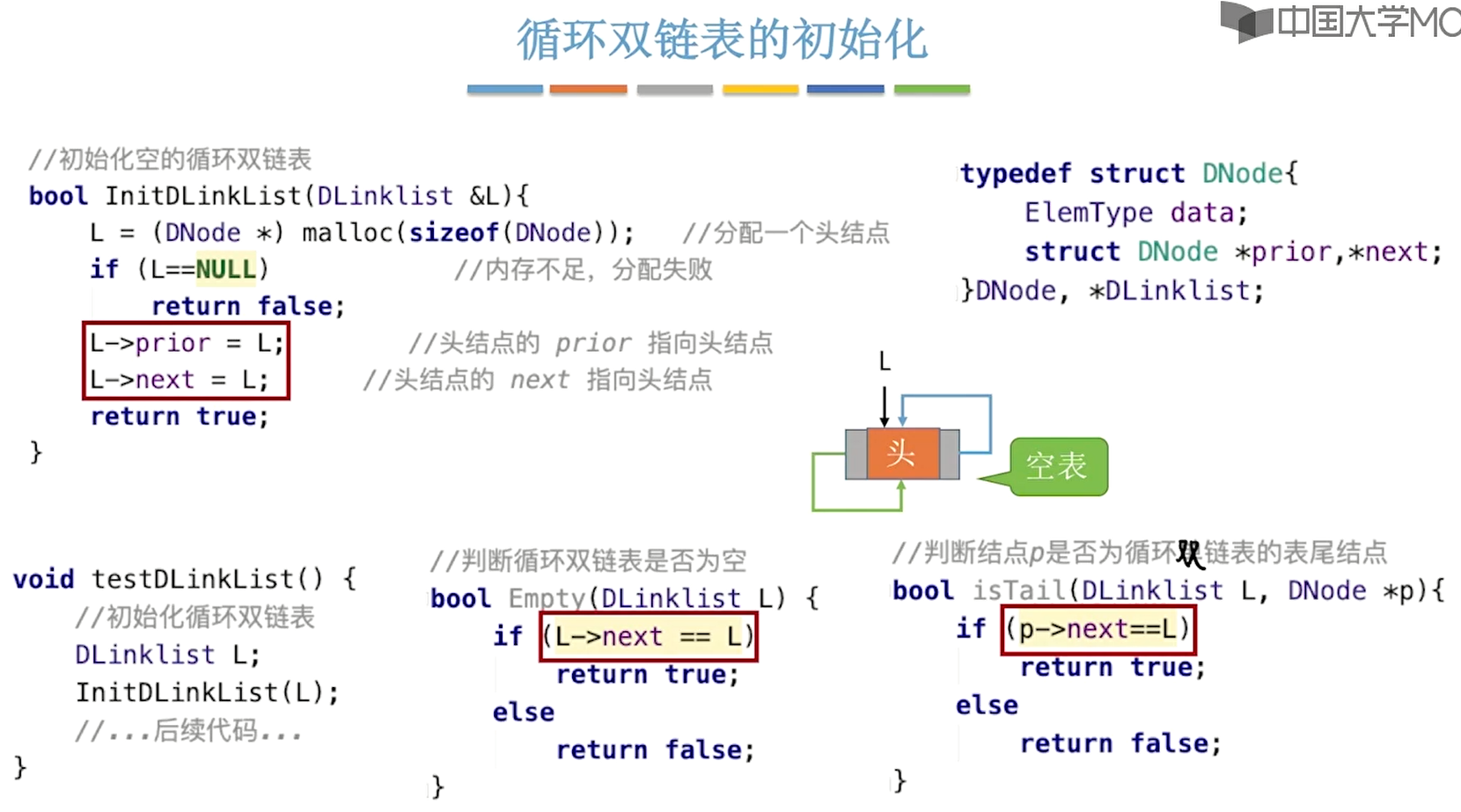
(1)初始化
1 | //定义结点结构体 |

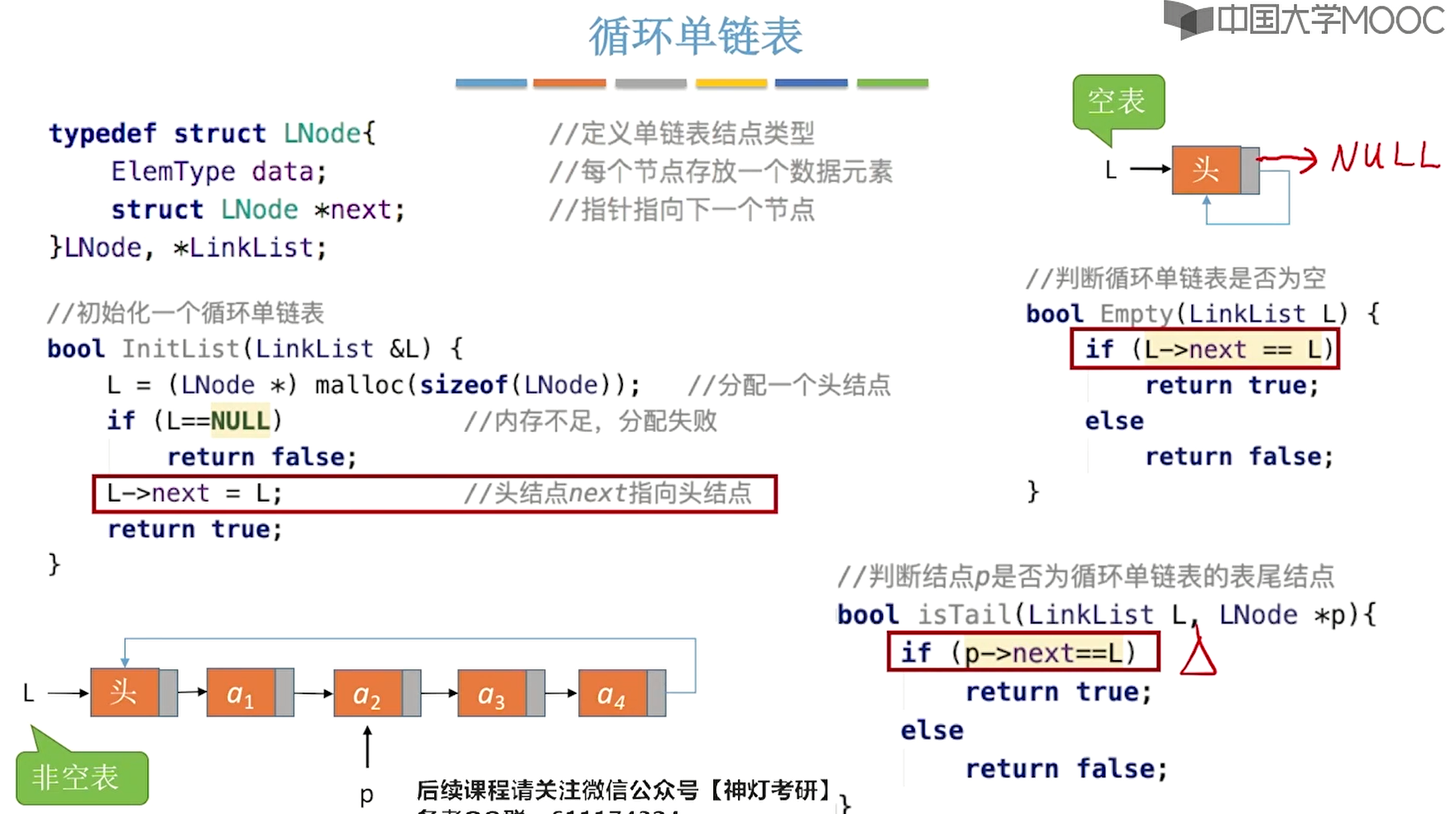
3、循环单链表
4、循环双链表
5、静态链表
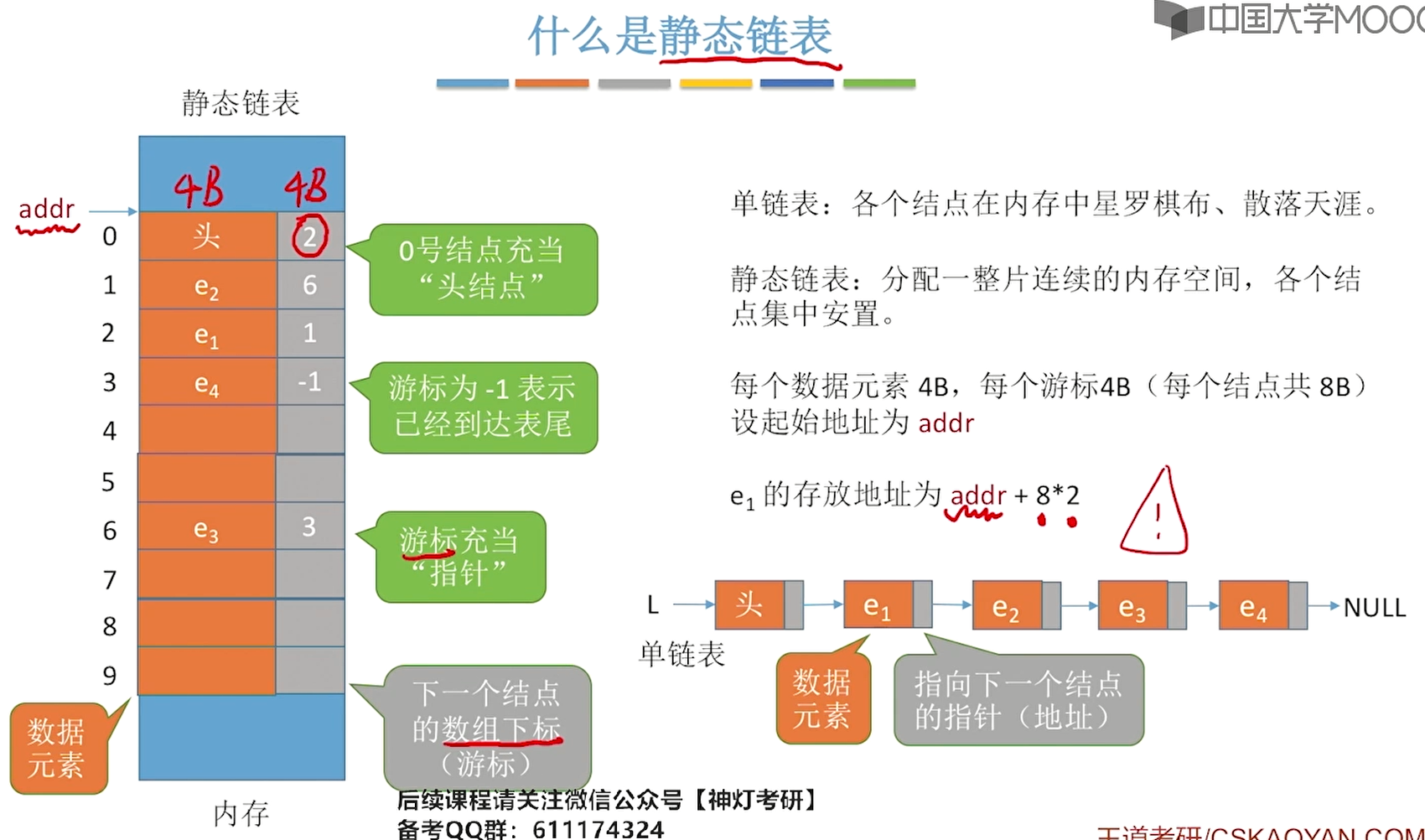
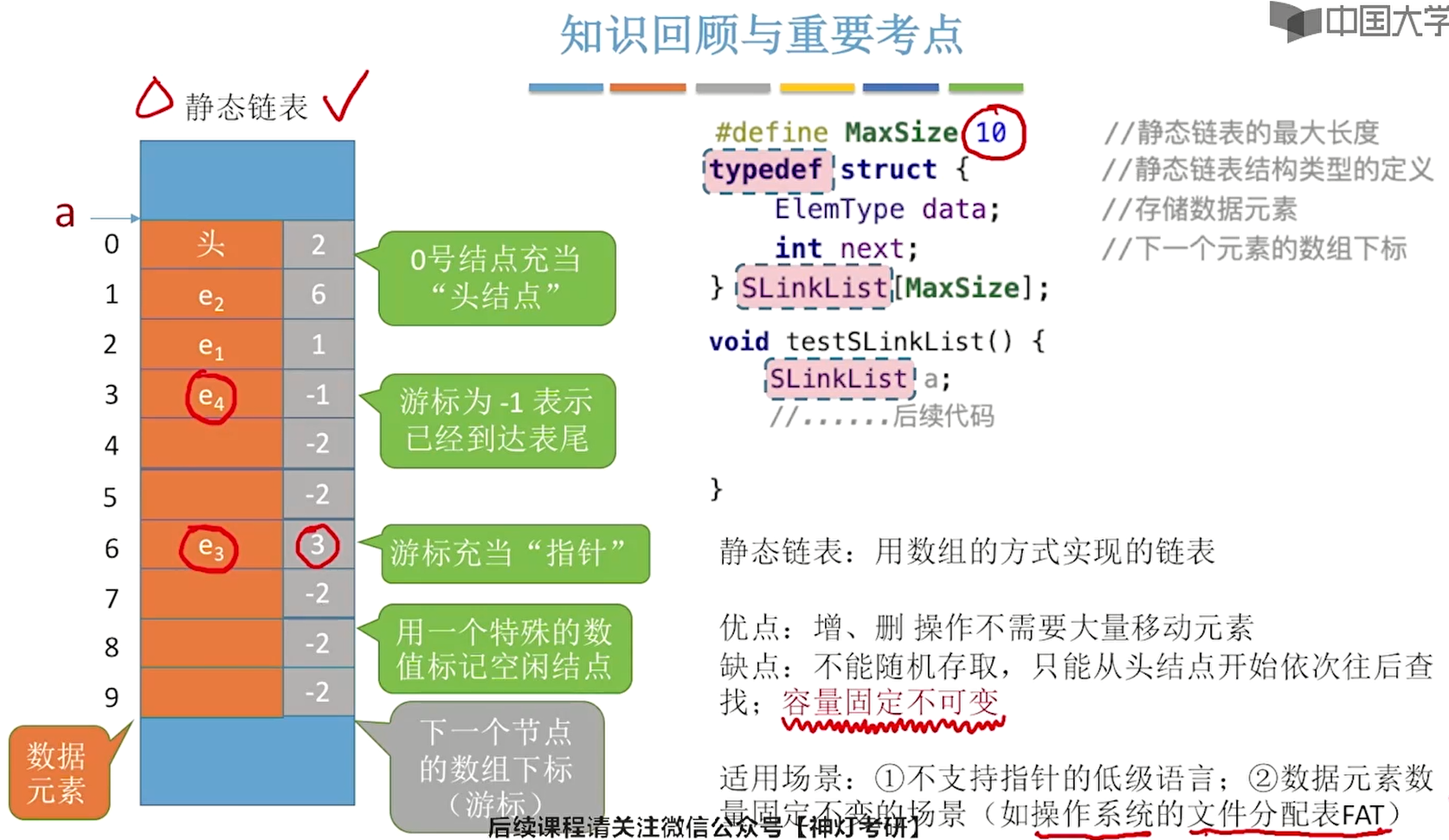
其实就是结构体数组,在内存中申请了一块连续的大空间,用来存放n个结构体结点。每个节点有数据域和游标/指针域。
6、顺序表和链表的比较
(1)逻辑结构
- 都属于线性表,都是线性结构。
(2)物理结构
- 顺序表
- 优点:支持随机存储,存储密度高。
- 缺点:大片连续存储空间分配不方便,改变容量不方便。
- 链表
- 优点:离散的小空间分配方便,改变容量也方便。
- 缺点:不可随机存取,存储密度低。
(3)基本操作总结对比
增、删、改(创销)、查
| 增 | 删 | 改——创 | 改——销 | 查 | 时间复杂度 | |
|---|---|---|---|---|---|---|
| 顺序表 | 定位到数组的目标序列,插入值,更改表长 | 定位到数组的目标序列,删除值,更改表长 | ①静态分配:创建结构体,结构体属性有两个——数据域和长度标识,数据域为一个数组,用来存放数据;②动态分配: | 逐项遍历数组元素并删除,最后更改表长标识 | 按值查找——逐项遍历对比;按位查找——随机访问 | O(n),主要来自移动元素 |
| 链表 | 先新建结点,再将节点插入其中。①单链表只能从头至尾循环遍历;②双链表可逆向遍历;③链表可任意遍历 | 先定位到目标节点,再清除数据域,然后更改前后指针,最后释放空间 | 先创建头指针,如果带头结点就把头指针指到头结点,不带头结点就把头指针指向第一个结点或自身 | 逐项遍历到尾结点,删除节点属性/数据域,更改前后指针,释放空间 | ①先判断是否是第一个结点或尾结点;②否,则循环遍历寻找目标 | O(n),主要来自于查找目标元素 |